Z-mind — 分布式ML任务执行与管理AI平台
在Docker中运行模型,跨GPU/CPU集群分配负载,管理队列,无停机扩容。
运行任意ML模型
在Docker容器中运行
任务负载均衡
跨服务器实时分配
高容错性
联邦架构保障稳定
API驱动管理
以及Web界面
离线就绪
可在隔离网络环境中运行
Z-mind 仪表盘
Web管理界面
GPU负载
78%
CPU负载
65%
适用人群与场景
何时需要立即使用Z-mind
当您拥有多个模型、任务量持续增长,且基础设施分散在不同服务器时,手动管理很快就会成为瓶颈。
Z-mind消除混乱:集中执行、分配算力,让任务处理变得可预测。
模型运行不稳定
GPU空闲而队列增长
难以查看状态和诊断错误
添加新模型处理程序缓慢
需要在隔离网络环境中运行
能力
统一的AI工作负载运行、编排与管控环境
容器优先执行
模型以Docker容器交付——依赖隔离与可复现环境
分布式执行
跨GPU/CPU服务器自动分配任务
负载均衡
队列优先级排序,最大化减少资源闲置
每模型队列
每个模型处理程序对应独立的RabbitMQ队列
监控与日志
状态、执行时间、诊断日志
API + Web界面
通过系统和界面管理任务
快速扩容
无需停止服务即可添加节点
离线就绪
镜像预构建后可在无网环境中运行容器
结果存储
PostgreSQL存储任务、元数据及透明历史记录
在分布式计算基础设施上托管服务与智能体
组合智能体与服务构建AI助手
工作原理
Z-mind任务处理流水线
提交任务
客户端通过API或UI提交任务
模型队列
任务进入所需模型的队列(RabbitMQ)
负载均衡
均衡器分析队列与服务器负载
执行
节点上的Pod Script启动容器并运行任务
持久化
结果与元数据保存至PostgreSQL
监控
状态与日志可在界面和API中查看
架构示意图
架构
稳定负载与弹性扩容的联邦架构
服务器以联邦方式组织,每个节点均可运行所需处理程序的容器。
任务队列按模型隔离,均衡器根据队列长度、当前服务器负载及活跃节点数量动态重新计算优先级。
API
Node.js
均衡器
Node.js
Pod Script
部署于计算节点
RabbitMQ
消息队列
Redis
优先级与快速键值
PostgreSQL
持久化存储
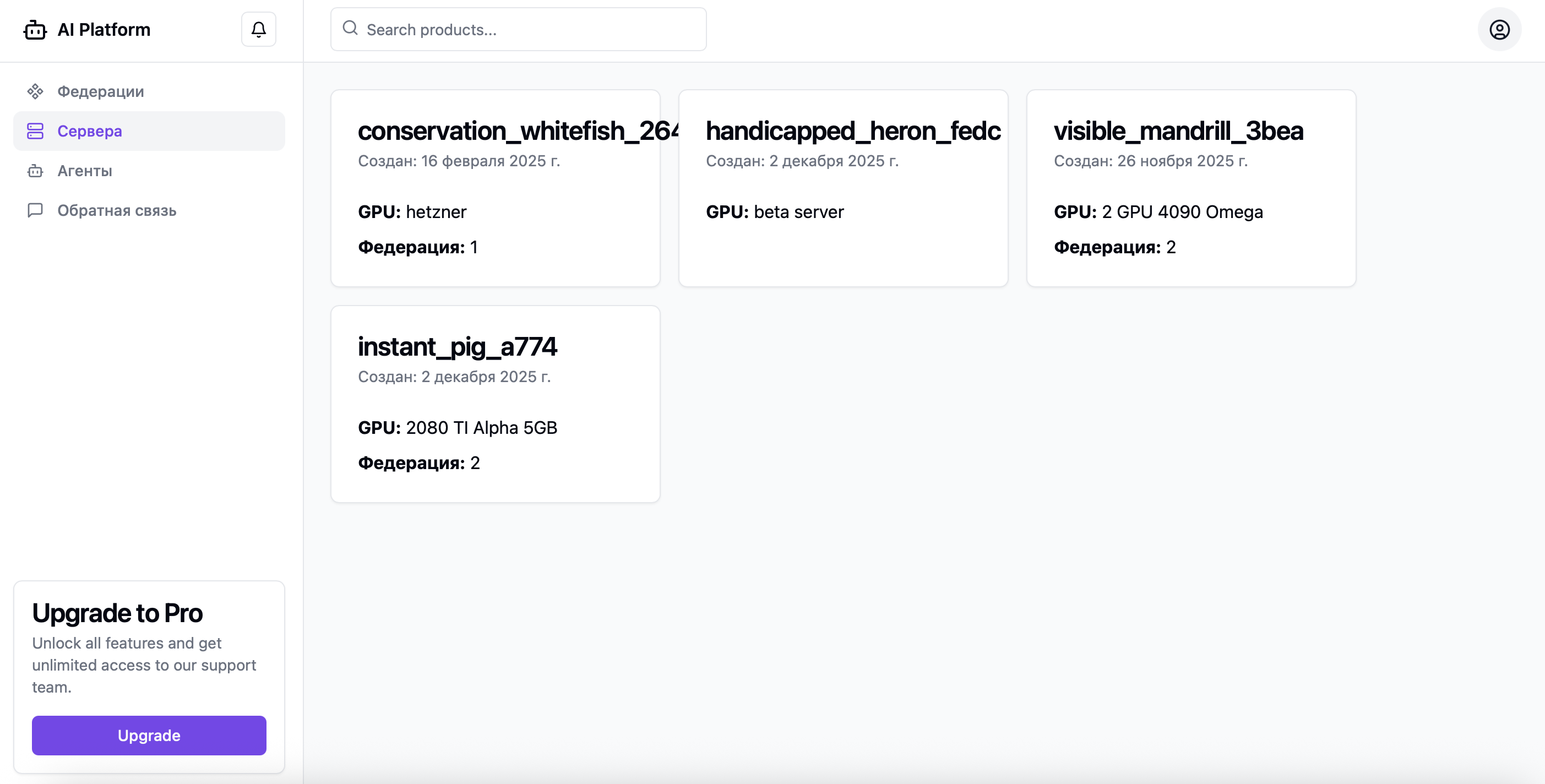
服务器监控与队列指标
快速开始
新模型无需重建平台即可接入
构建模型的Docker镜像
将镜像推送至镜像仓库
在管理面板中注册模型
开始向专属队列发送任务
应用场景
Z-mind快速见效的典型场景
批量文档处理
从大量文档中提取数据
批量图像/视频分析
并行使用神经网络处理媒体文件
并行模型测试
在同一数据集上比较多个ML模型
内部AI工厂
构建集中式AI基础设施
隔离网络环境中的AI服务
在安全隔离环境中无网络运行
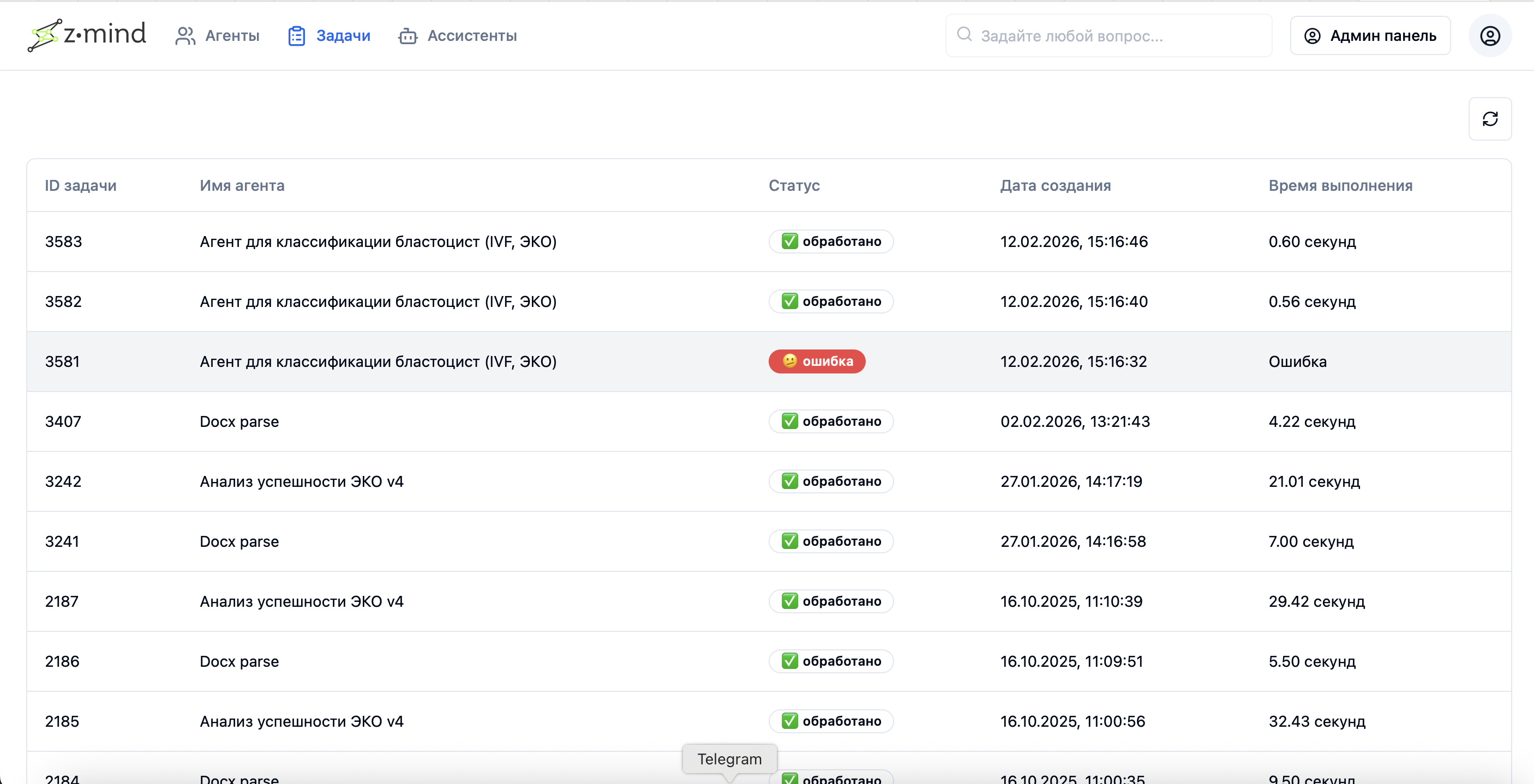
服务/智能体的任务处理结果(批处理输出)
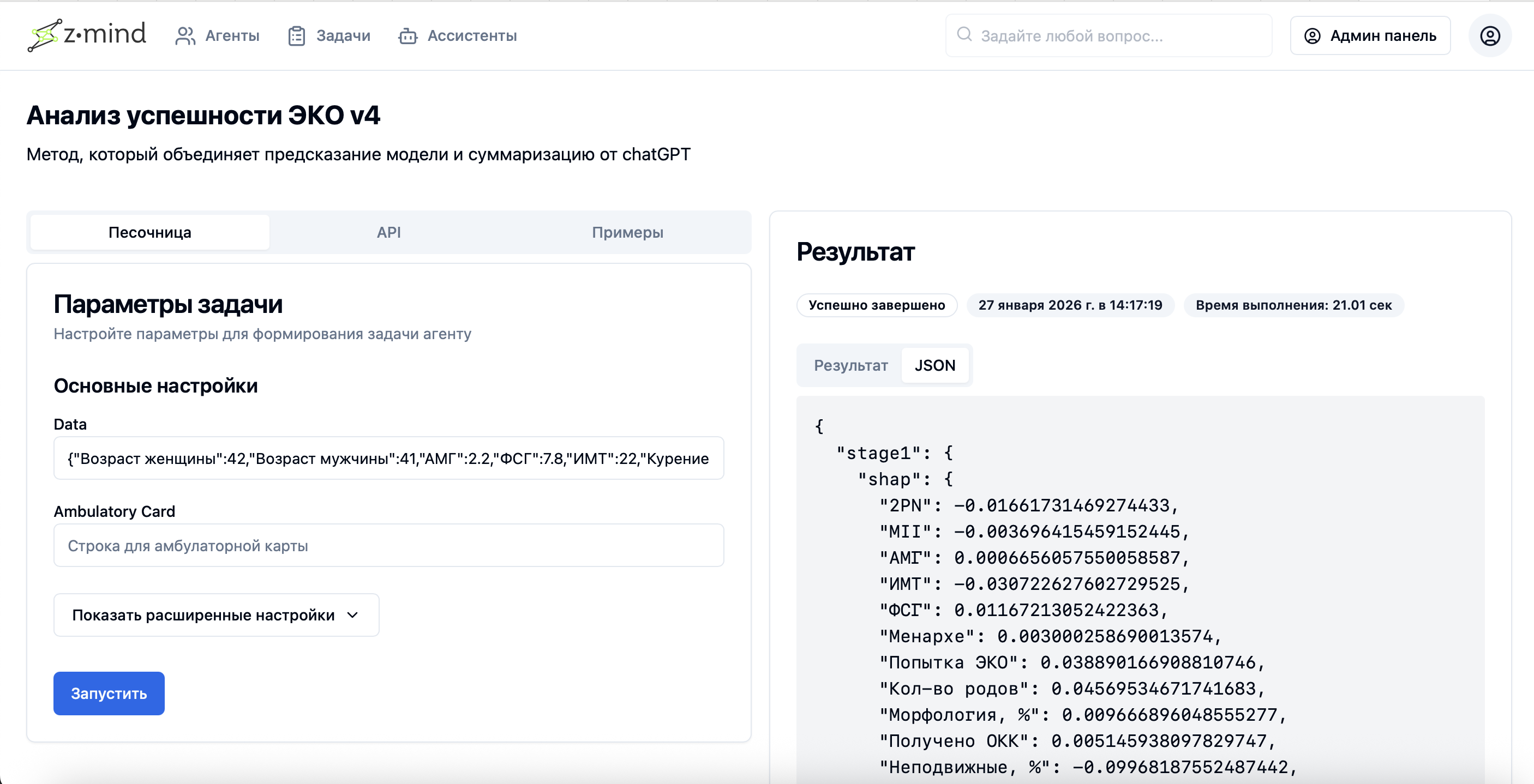
系统中特定模型处理的示例日志
集成
API优先:无缝接入现有系统,不中断业务流程
Z-mind通过API集成至现有基础设施。
可自动创建任务、获取状态、收集结果,并将平台嵌入您现有的ETL/ML/业务流程。
API示例
/tasks创建任务/tasks/{id}获取状态/tasks/{id}/result获取结果可靠性
生产环境中的稳定运行
按队列隔离任务
实时优先级控制
集中日志与可观测性
容器跨服务器可移植
支持离线场景
部署
灵活的部署方式
我们根据您的工作负载、安全要求和SLA量身定制配置方案。
本地部署
部署于客户自有网络边界内
私有云
专属独立环境
混合部署
部分本地,部分云端
成果
团队部署Z-mind后的收益
任务处理速度提升
最高340%
节点空闲时间减少
最高85%
新模型接入时间
从5天缩至2小时
执行透明度
100%任务可追溯
FAQ
常见问题
可以,只要模型打包为Docker镜像并在系统中注册即可。
支持。使用包含缓存权重的预构建镜像,平台可在隔离网络环境中运行。
通过向联邦中添加计算节点实现,无需更改任何客户端集成逻辑。
通过RabbitMQ队列、均衡器优先级排序、PostgreSQL数据持久化和日志监控实现。
通常只需选择1–2个目标场景、准备好镜像并接入API即可。
我们将在短期试点中演示Z-mind的实际效果
我们将进行架构咨询、评估负载、提出配置方案,并启动可量化成果的试点项目。