Z-mind — AI platform for distributed ML task execution and management
Run models in Docker, distribute load across GPU/CPU clusters, manage queues, and scale without downtime.
Run any ML models
In Docker containers
Task load balancing
Across servers in real time
High fault tolerance
Of federated architecture
API-driven management
And web interface
Offline-ready
Runs in air-gapped infrastructure
Z-mind Dashboard
Web management interface
GPU load
78%
CPU load
65%
Who needs it and why
When you need Z-mind right now
If you have multiple models, a growing task volume, and infrastructure spread across different servers, manual management quickly becomes a bottleneck.
Z-mind eliminates the chaos: centralizes execution, distributes compute, and makes task processing predictable.
Models run unreliably
GPUs sit idle while queues grow
Hard to see status and diagnose errors
Slow to add new model handlers
Need to run in an air-gapped environment
Capabilities
A unified environment for running, orchestrating, and controlling AI workloads
Container-first execution
Models are shipped in Docker — dependency isolation and reproducible environments
Distributed execution
Automatic task distribution across GPU/CPU servers
Load balancing
Queue prioritization and minimization of idle resources
Per-model queues
A dedicated RabbitMQ queue for each model handler
Monitoring & logs
Statuses, execution times, diagnostic logs
API + Web UI
Manage tasks from your systems and through the interface
Fast scaling
Add nodes without stopping the service
Offline-ready
Run containers without internet access when images are pre-built
Result storage
PostgreSQL for tasks, metadata and transparent history
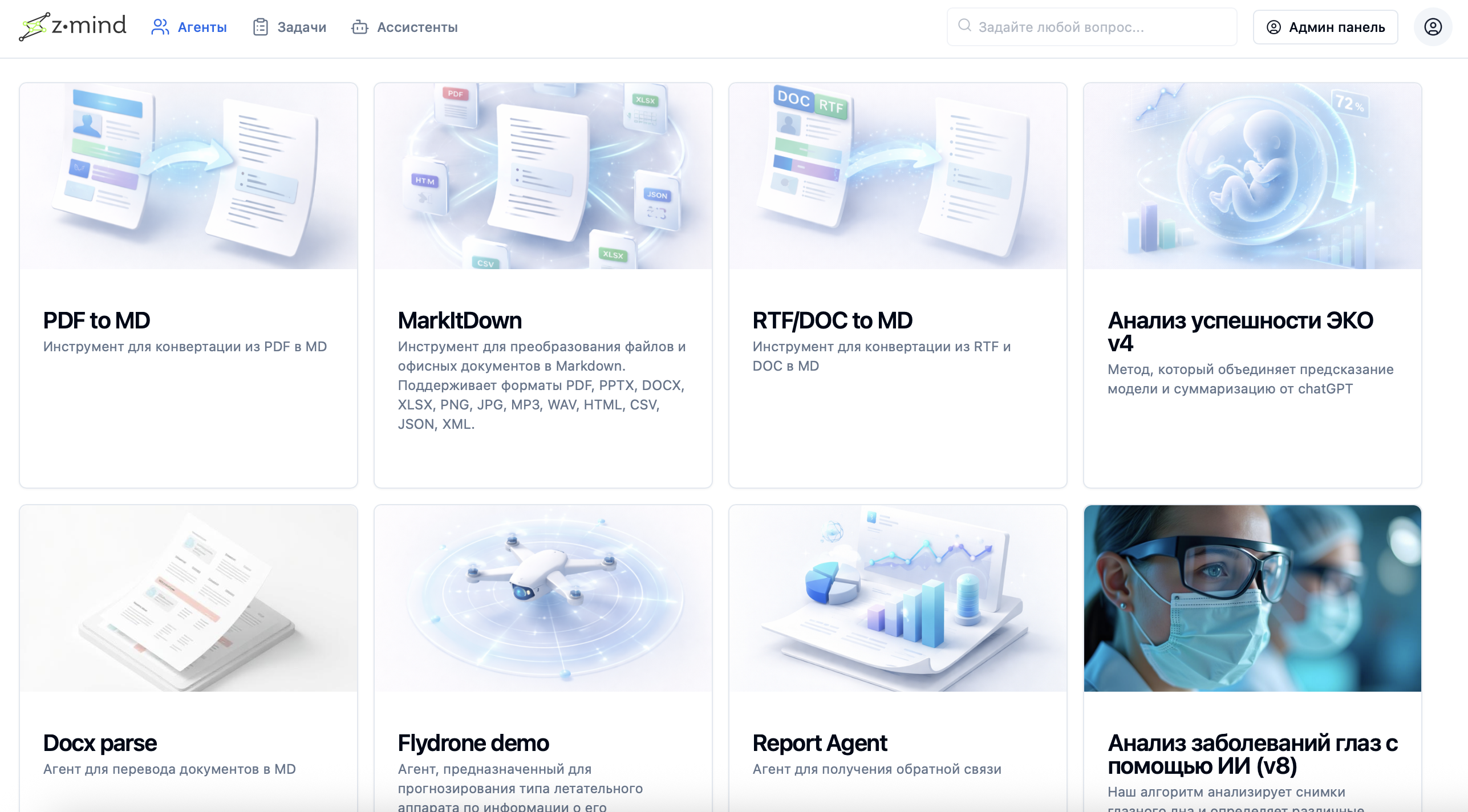
Hosting services and agents on distributed compute infrastructure
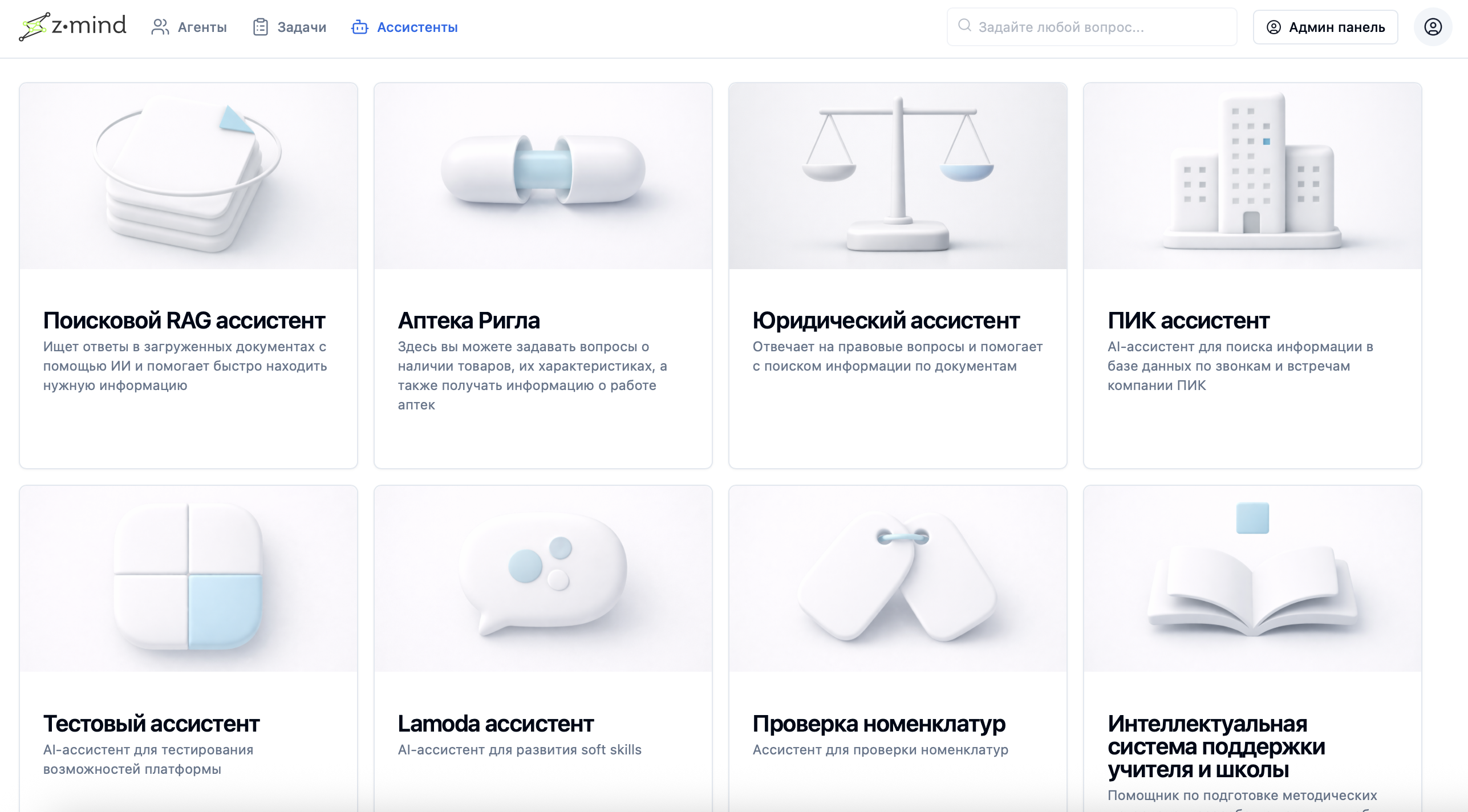
Combining agents and services to build AI assistants
How it works
Task processing pipeline in Z-mind
Submit task
Client submits a task via API or UI
Model queue
Task enters the queue for the required model (RabbitMQ)
Balancing
Balancer analyzes queues and server load
Execution
Pod Script on the node launches the container and runs the task
Persistence
Result and metadata are saved to PostgreSQL
Monitoring
Status and logs available in the interface and API
Architecture diagram
Architecture
Federated architecture for stable load and scaling
Servers are united in a federation where each node can run containers with the required handlers.
Task queues are isolated by model, and the balancer dynamically recalculates priorities based on queue length, current server load, and the number of active nodes.
API
Node.js
Balancer
Node.js
Pod Script
On compute nodes
RabbitMQ
Queues
Redis
Priorities and fast keys
PostgreSQL
Persistent storage
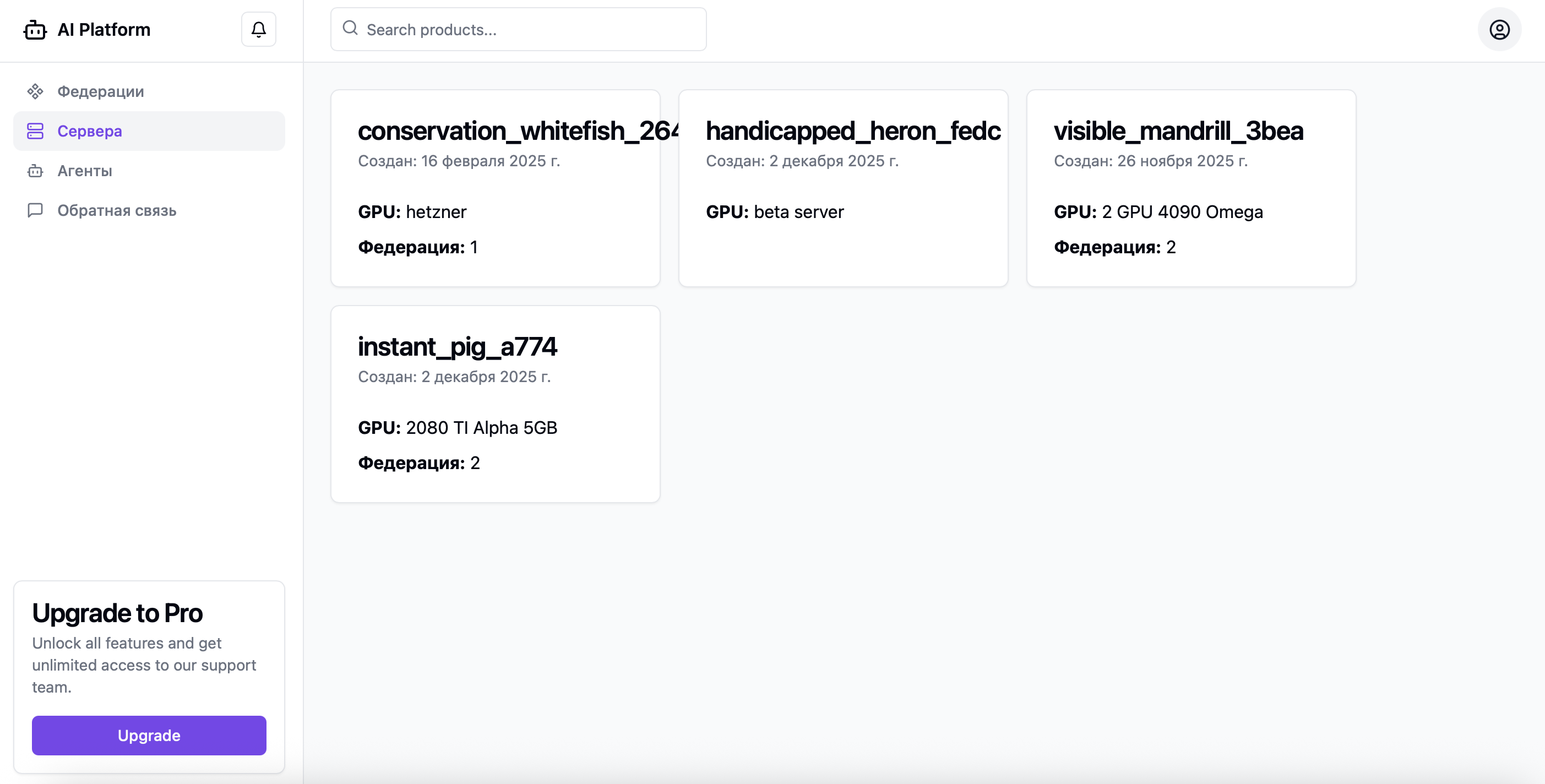
Server monitoring and queue metrics
Quick start
New models connect without rebuilding the platform
Build a Docker image of the model
Push the image to the registry
Register the model in the admin panel
Start sending tasks to the dedicated queue
Use cases
Typical scenarios where Z-mind delivers fast results
Bulk document processing
Extract data from large volumes of documents
Batch image/video analysis
Process media with neural networks in parallel
Parallel model testing
Compare ML models on the same data
Internal AI factory
Build a centralized AI infrastructure
AI services in an air-gapped environment
Run without internet in a secure enclosure
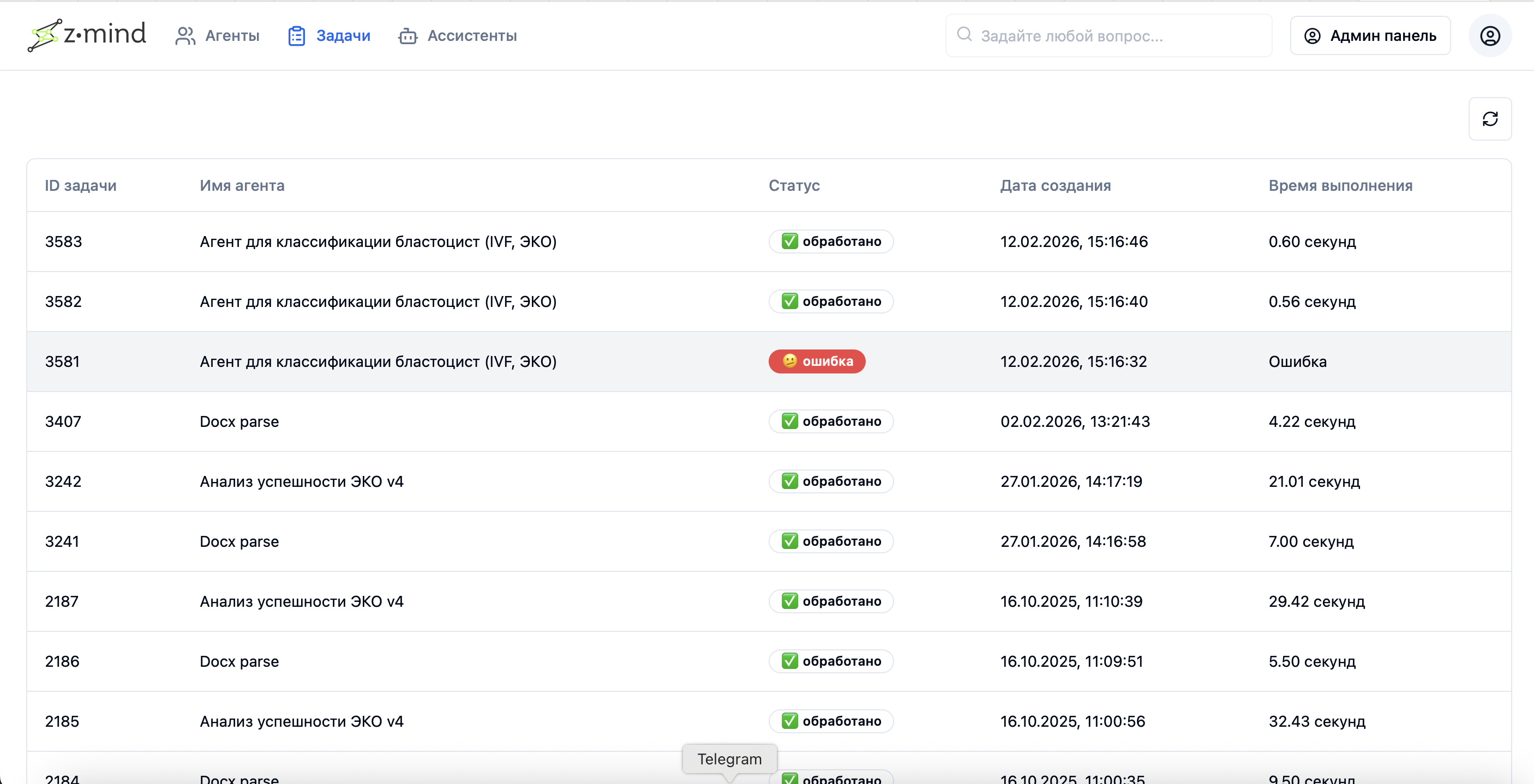
Task processing results from services/agents (batch processing output)
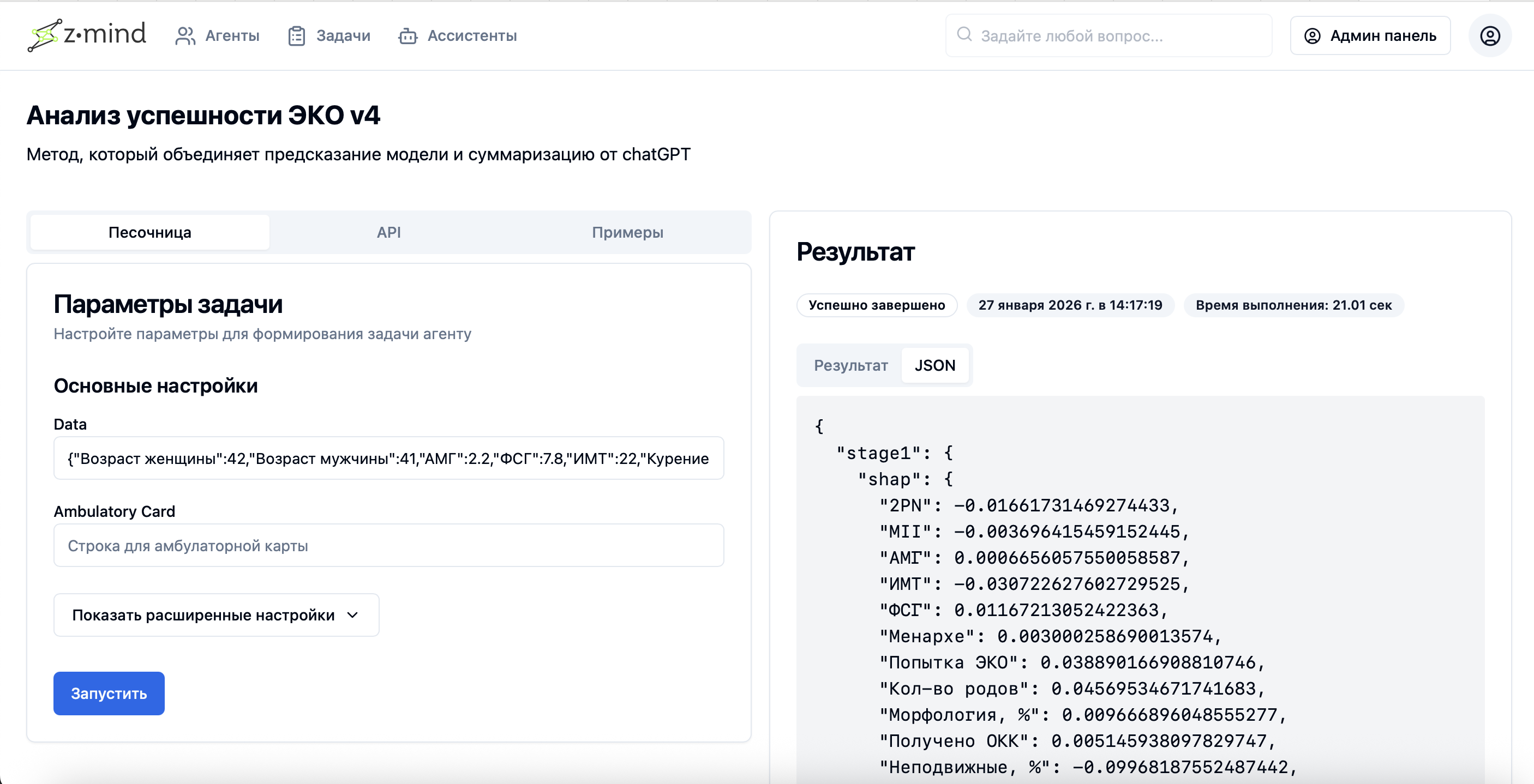
Example log for a specific model's processing in the system
Integration
API-first: plug into existing systems without disrupting workflows
Z-mind integrates into existing infrastructure via API.
You can automatically create tasks, retrieve statuses, collect results, and embed the platform into your current ETL/ML/business process.
API example
/taskscreate a task/tasks/{id}get status/tasks/{id}/resultget resultReliability
Stable operation in production environments
Task isolation by queue
Real-time priority control
Centralized logs and observability
Container portability across servers
Offline scenario support
Deployment
Flexible deployment options
We tailor the configuration to your workload, security requirements, and SLA.
On-Premise
Deployed within the customer's perimeter
Private Cloud
Dedicated environment
Hybrid
Part of capacity on-premises, part in the cloud
Results
What teams gain after launching Z-mind
Task processing speed-up
up to 340%
Reduction in node idle time
up to 85%
Onboarding a new model
from 5 days to 2 hours
Execution transparency
100% of tasks
FAQ
Frequently asked questions
Yes, as long as the model is packaged in a Docker image and registered in the system.
Yes. With pre-built images that include cached weights, the platform can run in an air-gapped environment.
By adding compute nodes to the federation without changing any client integration logic.
Through RabbitMQ queues, balancer prioritization, PostgreSQL data persistence, and log monitoring.
Typically it is enough to choose 1–2 target scenarios, prepare the images, and connect the API.
We'll show Z-mind on your scenario in a short pilot
We'll run an architecture session, assess the load, propose a configuration, and launch a pilot with measurable results.